By Venu Bolisetty (Engagement Manager, 28Stone), Vitalijs Ozornins (Development Lead, 28Stone)
Generative AI (GenAI) agents built on Large Language Models (LLMs) are emerging as powerful tools for everything from code development to storytelling. In the summer of 2023 here at 28Stone, as we marveled at the capabilities of ChatGPT and other GenAI solutions, we realized their unclear data protection policies could hinder their usage for our clients. The opacity of their model training and operational processes—often described as a ‘black box’—raises concerns about safeguarding proprietary and sensitive information, particularly for banks and highly secretive hedge funds. In response to a New York Times lawsuit, OpenAI has also acknowledged that regurgitation is a rare bug that they hope to eliminate. Despite these challenges, many enterprises have decided the benefits outweigh the risks, eager to leverage GenAI’s potential. However, discussions with our clients have revealed apprehensions regarding the security of their proprietary data. This blog post explores strategies for employing these advanced technologies securely, ensuring our clients can harness their capabilities without compromising data controls, protections and ethical use.
Our early adventures (or mis-adventures) with LLMs
While privacy and control over data were crucial factors in our early approach, other factors such as hardware limitations, ease-of-use and time-to-completion for the prototype were equally important. We excluded several well-performing publicly available solutions due to privacy issues, while local GPU-enabled LLMs were impractical because a majority of our employees did not have easy access to GPUs. Therefore, we settled on local CPU-enabled LLMs for our initial exploration.
Next, we needed to come up with a tangible use case for prototyping a solution. As a software delivery firm focused primarily on the capital markets, we were curious if these LLM-based solutions could become a crucial part of a financial analyst’s tool belt. We were skeptical about the ability to project financial statements into the future, but we were fairly confident that these models could digest publicly available information from the financial statements and answer relevant questions. For example, could a model fine-tuned on a historical set of financial statements of a company identify any trend changes in the risks for that company or even the whole sector? Could the model generate an income statement for the next two quarters and list the assumptions?
On the technical side, as a second use case we wanted to test our hypothesis that these models could help cross-train developers in different languages as well as help complement UI-only or BE-only developers to function as full stack developers. Could we train a model on our internal code repositories and have it implement simple new features? As a software consulting company, this has tremendous potential for us to efficiently train and deploy teams based on client and project needs.
Given these constraints and use cases, our first prototype employed LangChain to run the GGUF model from Huggingface. This prototype contained two stages: the first involved using a model to generate embeddings from data sources; i.e., transforming words and phrases into vector representation that allows machine learning models to use this data. For embeddings, we employed HuggingFaceEmbeddings and the ‘ggrn/e5-small-v2’ model. The vectors representing these embeddings were then stored in Chroma (a vector score.). In the second stage, the LLM utilized the vector store and embeddings to answer questions about the documents. This implementation gave us an introduction to this space, however, we quickly realized there were several drawbacks to this approach. The response time was slow and updating the model required changes to our code. As we learned more and developed a deeper appreciation for the complexity, we identified a few changes that would significantly improve the quality and performance of our initial solution.
The road to GPU and LlamaIndex
Our first idea, inspired by the PrivateGPT project, was to move the data ingestion into a separate process allowing us to update to a model-agnostic prototype. Yet, this CPU-based solution routinely took several minutes to respond to simple queries. While the quality of responses was relatively good, the time to respond was unacceptable and that led us to exploring GPU-based solutions. We initially prototyped a GPU solution using notebooks on Google colab to validate our approach, but then quickly moved to RunPod for a scalable and sustainable architecture. RunPod’s service, offering GPU-enabled instances and standard templates, gave us the foundational building blocks. If we were to implement this today, we would probably choose VertexAI on the Google Cloud Platform.
Around this time we also uncovered LlamaIndex, a framework developed to help with the implementation of Retrieval Augmented Generative (RAG) applications. Rather than continue with our custom implementation for the prototype, we pivoted to using this framework because it had built-in support for ingesting multiple document types. Furthermore, the framework made it easy to integrate with most popular models and to build multiple indices and other custom configurations we found to be important to our use cases.
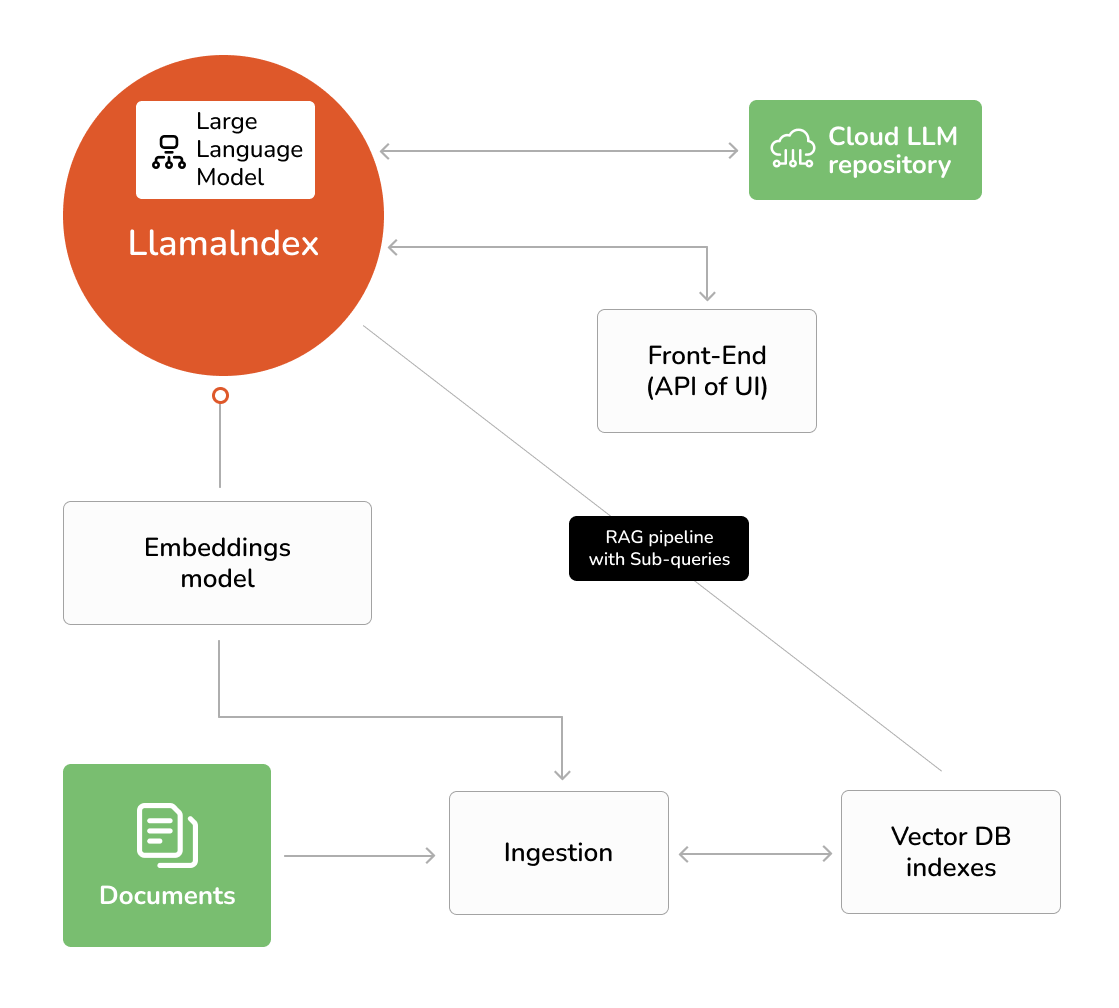
Optimizations
With confidence in the LlamaIndex framework and the deployed architecture, we employed certain optimizations and tinkered with GPU settings to improve the performance and quality of the solution. We include a sample of the most interesting optimizations worth sharing.
Multiple Indexes
Almost immediately we found the use of a single index on all ingested data to be limiting. After feeding the model a code base developed on Python, React and Typescript, we asked it to generate UI code to get and display all the inventories in a simple table. The generated code correctly identified the different steps in the algorithm, but it also contained excerpts of Python code. When we re-deployed the solution using separate indexes for the UI and BE code repositories, the generated code again correctly identified the solution but also limited itself to React and Typescript.
Data cleansing and formatting
During the ingestion of certain HTML-based documents representing financial statements of public companies, we needed to implement an additional layer of data cleansing before the document could be fed through the normal ingestion. Furthermore, responses to questions that required an understanding of the relationship between elements in a table were consistently underwhelming. While we never got to test it, we feel confident that building separate indexes for structured data, such as tables, embedded in the document should significantly improve the quality of those responses.
Performance Optimization
The Llama2 model was generally fast with the default settings but we noticed that not all GPU cores were being utilized effectively. By increasing the number of threads to 4 and the number of GPU layers to 400, it helped parallelize workload along multiple cores leading to improved performance.
Results of our LLM tests
With these optimizations, we saw some interesting early results for our LLM test use cases. The performance (i.e. speed of response) matched publicly available solutions, such as ChatGPT. As we originally feared, the generated projections on the financial statements did not end up providing useful output. We suspect that better defining relationships between the different fields on a financial statement could yield further improvements and is an area for further investigation.
On the other hand, the code generation showed some impressive results - good enough such that we plan to incorporate additional code repositories and offer this tool to our developers interested in cross-training on different languages. The results are promising enough that we feel confident proposing this approach for those seeking to use LLMs and Generative AI, but are not comfortable sharing private and internal data with the public AI services.
Some Parting Thoughts
Just as we were putting final touches on this post, Open AI showcased stunning early results from Sora - their text-to-video generation solution. Less than 24 hours later, Google Gemini announced an increase in token size to 1 Million which will allow for massively increased context. The components of the custom prototype that we developed only 6 months ago are now fully managed service offerings. The pace of progress in both the models and the ecosystem is dizzying. Identifying a starting point can seem overwhelming. If you are unsure where to begin, here are a few recommendations and takeaways based on our experience.
- Start by identifying a small time-intensive task, build a prototype and validate the quality of the prototype before taking on the full implementation. At 28Stone, we structure our projects into two distinct phases: a short time-boxed initiation phase to conduct analysis followed by an implementation phase. For clients exploring AI implementations with us, our primary goal of the initiation phase is the development and validation of a prototype.
- We recommend using a popular base (or foundational) model from the leading providers (OpenAI, Meta, Anthropic or Google) for the initial prototype and utilizing RAG to train on your internal data. For some of your problems, you may get desired results using a combination of an effective prompt and prompting strategy to get the most out of your model. By utilizing a model-agnostic framework you can also include a bake-off between models during the initiation phase.
- Carefully track and maintain training costs as well as other infrastructure costs during the initiation phase to get a sense of the estimate for the “all-in” cost associated with production workloads and implementation. It is equally important to evaluate the results of your implementation to determine if further model fine-tuning is necessary.
For more information
If you have any questions, feedback or are interested in learning more about our AI initiatives in our 28Stone Lithos Lab, please don’t hesitate to contact us.
Read our related blog post on GenAI:
There’s No Slowing Down: Where Do We Go With Generative AI in 2024?